I am going to attempt to debunk almost every WordPress SEO “Expert” article ever written, and in some respects, this article even debunks some of the things I have written in the past.
This article does not reference Google Toolbar PageRank in any way.
First of all, you are going to need to do a little homework.
Eric Enge interview with Matt Cutts
The Eric Enge interview with Matt Cutts was truly exceptional and revealed some gotchas that for some reason continue to be circulated.
Key takeaways
Matt Cutts: … Now, robots.txt says you are not allowed to crawl a page, and Google, therefore, does not crawl pages that are forbidden in robots.txt. However, they can accrue PageRank, and they can be returned in our search results.
Matt Cutts: … So, with robots.txt for good reasons we’ve shown the reference even if we can’t crawl it, whereas if we crawl a page and find a Meta tag that says NoIndex, we won’t even return that page. For better or for worse that’s the decision that we’ve made. I believe Yahoo and Microsoft might handle NoIndex slightly differently which is little unfortunate, but everybody gets to choose how they want to handle different tags.
Eric Enge: Can a NoIndex page accumulate PageRank?
Matt Cutts: A NoIndex page can accumulate PageRank because the links are still followed outwards from a NoIndex page.
Eric Enge: So, it can accumulate and pass PageRank.
Matt Cutts: Right, and it will still accumulate PageRank, but it won’t be showing in our Index. So, I wouldn’t make a NoIndex page that itself is a dead end. You can make a NoIndex page that has links to lots of other pages.
For example, you might want to have a master Sitemap page and for whatever reason NoIndex that, but then have links to all your sub Sitemaps.
I have just provided a couple of highlights, I am not attempting to replace a need for visiting the site I am citing. This is something I hate seeing, when people take other people’s content and repurpose it, thus making the original article worthless.
There are a few other gotchas in there, I suggest you read it 2 or 3 times to really understand what was said, and what wasn’t said.
Dangling Pages
One of the best descriptions of dangling pages is on the Web workshop site, though they are assuming that links are totally taken out of the equation based on what they quote from the PageRank paper.
“Dangling links are links that point to any page with no outgoing links. They affect the model because it is not clear where their weight should be distributed, and there are a large number of them. Often these dangling links are simply pages that we have not downloaded yet……….Because dangling links do not affect the ranking of any other page directly, we simply remove them from the system until all the PageRanks are calculated. After all the PageRanks are calculated, they can be added back in without affecting things significantly.” – extract from the original PageRank paper by Google’s founders, Sergey Brin and Lawrence Page.
Alternate interpretation
This is just an aside, as the amount of juice lost to dangling pages currently is hard to determine, and could be handled differently
They are assuming that if page A links to 6 other pages, 5 of them being dangling links, then the website will be treated as only having 2 pages until the end of the calculation.
While I haven’t delved into the maths (and probably couldn’t through lack of information and lack of knowledge), it also seems to me that at the time the pages are taken out of the cyclic calculation, a percentage of the link value can still be taken with them.
Thus though the site for cyclic calculations will be just 2 pages, the link from A to B might only transfer 1/6 of the juice on each cycle.
At the time the original paper was written, Google only had a small proportion of the web indexed due to hardware and operating system restraints.
In modern times they have a lot more indexed. Thus a more complex way of handling dangling pages could be possible.
More food for thought, a link to a page that is considered supplemental could be treated as a full link or as a link to a dangling page, or some other variant.
Even more food for thought, a site with multiple interlinked pages with no external links at all could be looked on as a “dangling site.”
Ultimately what is important is that dangling pages are a juice leak, though it’s hard to determine exactly how much
Additional Research On Link Juice Flow
I have referenced these works before, and I am just going to keep on referring people to them.
- SEOFastStart by Dan Thies – a good introduction to SEO, and also introduces the ideas of controlling juice around a website – no email signup required
- Revenge of the Mininet by Michael Campbell – a timeless classic as long as PageRank continues to be important – the download page isn’t hidden if you really don’t want to sign up to Michael’s mailing list, but I have been on his list for years.
- Dynamic Linking by Leslie Rhode – A bonus that comes with Revenge of the Mininet
I mentioned these is a comment on SEOmoz recently in a discussion on PageRank, and for some reason, my comment received just 2 up votes and one down vote.
I don’t gain in any material way from promoting these free e-books, though I might gain some goodwill. The main reason I link to them is that they are a superb resource, and it saves me countless hours writing beginners material.
OK, onto some debunking.
Blocking Pages With Robots.txt Creates Dangling Pages On The First Tier
In the quoted paragraph above, Matt clearly states that pages blocked with Robots.txt still accumulate juice from the links they receive.
Those pages don’t have any external 2nd tier links that are visible to a bot. Thus they are dangling pages.
How much juice they leak depends on how Google currently factor in dangling pages, but Matt himself suggests not to create dangling pages.
If you read any SEO Guide that suggests that the ultimate cure for duplicate content is to block it with robots.txt, I advise you to might want to question the author about dangling pages.
Meta NoIndex Follow Duplicate Content
This is a better solution than using Robots.txt because it doesn’t create dangling pages. Links on a duplicate content page are still followed. However, both internal and external links are followed and thus are leaking, often multiple leaks for the same piece of content when using CMS systems such as WordPress which create site-wide links in the sidebar when using poorly designed themes, plugins, and especially WordPress Widgets.
If you read an article suggesting using Meta Noindex Follow, ask the author how they are controlling external links on duplicate content pages.
Meta NoIndex Nofollow Duplicate Content
If you use Meta Noindex Nofollow, while this is handled slightly differently by Google to Robots.txt, as the page won’t appear in search results, it is still a page accumulating Google Juice if you link to it, another dangling page or node.
Second tier leaks from the page won’t leak, but the page as a whole will leak depending on how Google is currently handling dangling pages.
I don’t see people recommending this frequently, but as with Robots.txt, ask the author about dangling pages.
Dynamic Linking & rel=”nofollow”
Extensive use of Nofollow and other forms of dynamic linking are the only way to effectively prevent duplicate content pages in some way having an effect on your internal linking structure and juice flow. The Wikipedia page on Nofollow really isn’t correct.
The Dangling Sales Page
To finish, I want to give you an example of how a sales page that previously might have benefited from lots of links can easily be turned into a dangling page and efficiently discounted from cyclic PageRank calculations.
Sales pages started off just as a single page with no links:

Despite all the links coming to the site from external sources, this website is a dangling page, thus excluded from iterative PageRank calculations. It might still benefit from anchor text and other factors, but it effectively is not part of Google’s global mesh and passes on no influence.
Add Legal Paperwork And Reciprocal Links Directory:
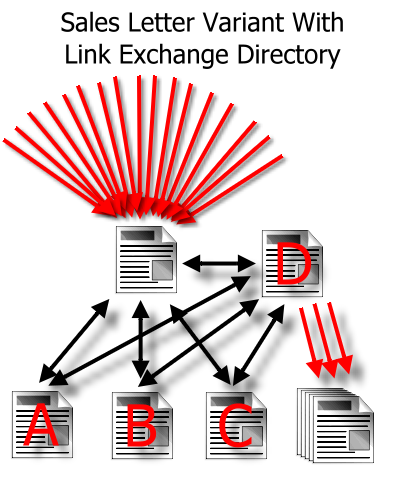
A much more structured site, and while it gains some benefit from reciprocating links, two factors are almost universally overlooked.
- No Longer A Dangling Page – because the site now has external links, it is valid as part of the global ranking calculations. Other pages as mentioned above were previously stating that the amount of juice passed to dangling pages was minimal so this could be potentially a huge boost.
- More Pages Indexed – it is only a few pages, but with PageRank, it is often not just how much juice you have flowed into a site, but what you do with it.
The reciprocal low-quality links might not have had a huge amount of value compared to the benefit of being a member of the “iteration club” and having a few more pages indexed.
Add a link to the designer

Some early single page sales letters were not dangling pages, but didn’t benefit from any internal iterations, and acted as a conduit of juice to their web design firm.
The Danger of Using Nofollow or Robots.txt on Unimportant Pages
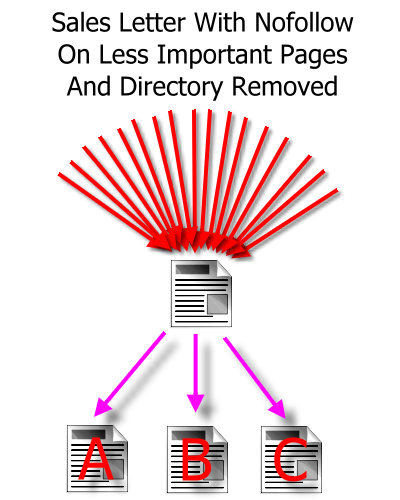
I have actually seen this on a few sites:
- Reciprocal Link Directory Removed
- Link to web designer removed
- Nofollow added to legal papers that are looked on as being unimportant
Such a website is now out of the iteration club, it is a dangling page as it is no longer voting on other pages.
My Own Gotcha
I mentioned that this catches me out as well.
A while ago I wrote an article about linking to Technorati being a problem. It might still be true, but the amount of juice lost through such links might also be lower than I thought, due to Technorati using meta nofollow on every page. Technorati tag pages are themselves dangling pages with no external links.
Wikipedia and Digg, on the other hand, are not dangling pages. They still have external links to other sites, and thus any links to them are part of iterative calculations.
I would still say it is best to have tags pointing to your own domain tag pages and to use nofollow on links to Wikipedia and Digg, though with Digg I suggest that is only with links to submission pages which contain no content.
Stumbleupon is also tricky – there are no external links from individual pages, but there is extensive internal linking.
With Digg and Stumbleupon, profiles rank extremely well, so you can use them for reputation management even if you get no juice direct from the profile.
I think I was the first to describe Wikipedia as a black hole of link equity, explained why you should nofollow Wikipedia extensively, and was one of the first to promote Ken’s Nofollow Wikipedia plugin.
You would have thought in 10 months they would have come up with an alternative to using nofollow on all those outbound links.
They do however link out to a few trusted sites without nofollow, from just a few pages. I suppose Google does still allow them to be part of their iterative calculations.
Another Own Gotcha
This isn’t 100% something I can fix. I have suggested people use robots.txt on certain sites knowing it wasn’t the perfect solution.
You might notice on this site that I don’t use an extensive robots.txt, and the design of my site structure is deliberate, but then at the same time I use nofollow with lots of custom theme modifications and should use it a lot more.
Eventually, I will come up with solutions to make things a little easier.
Tools In The Wrong Hands Can Be Dangerous
Using Robots.txt and Meta Noindex, Follow as a cure for duplicate content is an SEO bodge job or SEO band-aid. It may offer some benefits depending on how dangling pages are being handled but are certainly not an ideal solution due to some leaks that typically remain or dangling pages that are created.
Leave a Reply